The write flow in ectd.
Overview map
The best way to learn how a distributed storage system work is to analyze the execution flow of one of its basic operations.
Etcd opensource code provide a picture describe a write workflow on leader node. Let’s start with it:
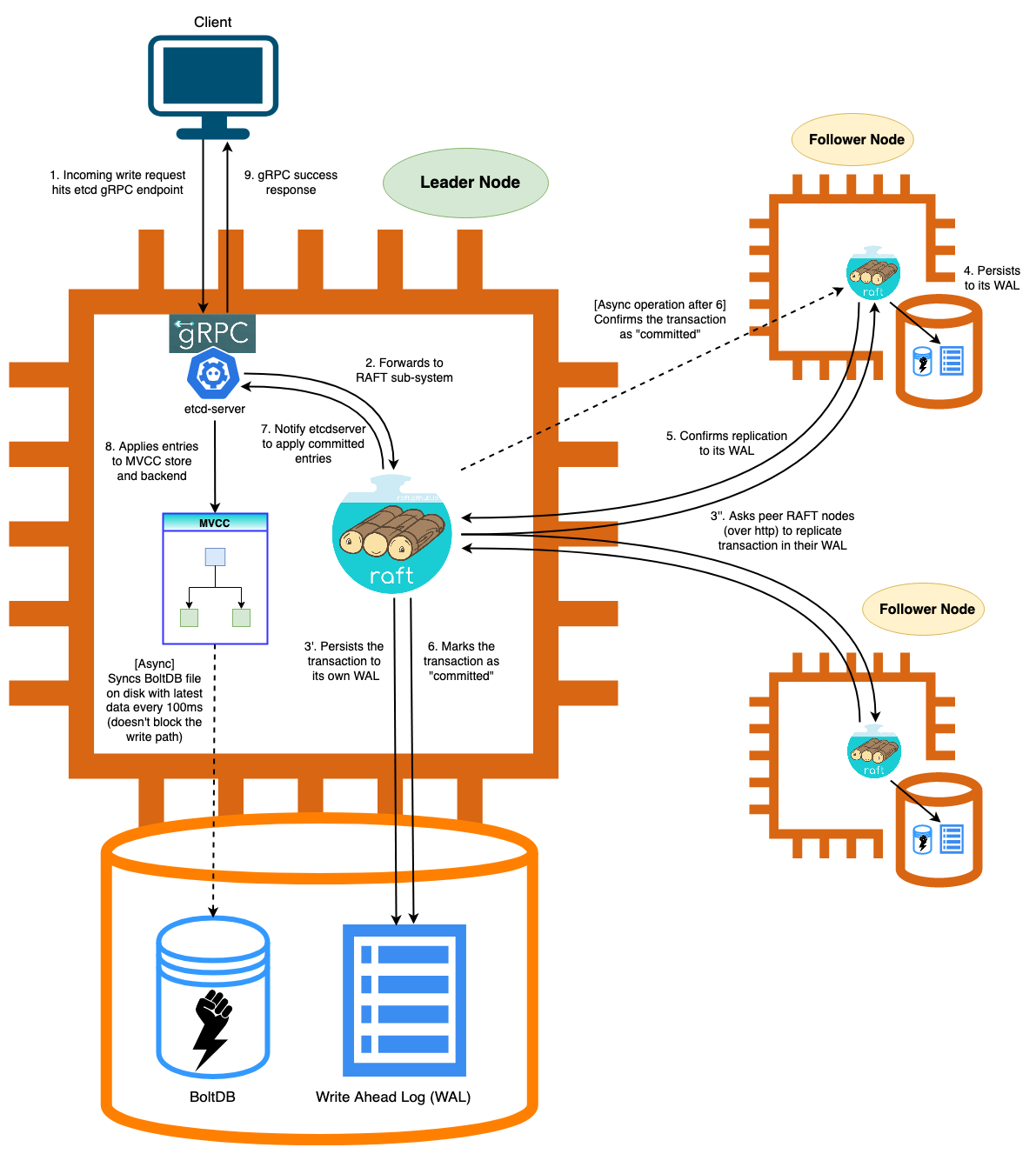
Figure 1
When we execute a put command with etcdctl.
etcdctl put mykey "this is awesome"
We well create a grpc client and call Put Rpc to comminicate with etcd server
code file : [https://github.com/etcd-io/etcd/blob/main/etcdctl/ctlv3/command/put_command.go](https://github.com/etcd-io/etcd/blob/main/etcdctl/ctlv3/command/put_command.go)
core logic:
// putCommandFunc executes the "put" command.
func putCommandFunc(cmd *cobra.Command, args []string) {
key, value, opts := getPutOp(args)
ctx, cancel := commandCtx(cmd)
resp, err := mustClientFromCmd(cmd).Put(ctx, key, value, opts...)
cancel()
if err != nil {
cobrautl.ExitWithError(cobrautl.ExitError, err)
}
display.Put(*resp)
}
mustClientFromCmd create and return an *clientv3.Client, Within the Client implementation, a Put RPC request is sent to the etcd server.
We can find the RPC definition in file
https://github.com/etcd-io/etcd/blob/main/api/etcdserverpb/rpc.proto
Now, let’s look at the architecture diagram below.

Etcd use gRPC-Gateway for provide etcd’s APIs in both gRPC and HTTP/JSON format at the same time, gRPC-Gateway converts HTTP requests into gRPC messages.
So we only need to focus on the implementation of the gRPC service.
We can find the ectdserver Put implementation code in https://github.com/etcd-io/etcd/blob/main/server/etcdserver/v3_server.go#L142
- This is the step1 flow in Figure1 - Incomming write request hits etcd gRPC endpoint.
func (s *EtcdServer) Put(ctx context.Context, r *pb.PutRequest) (*pb.PutResponse, error) {
ctx = context.WithValue(ctx, traceutil.StartTimeKey{}, time.Now())
resp, err := s.raftRequest(ctx, pb.InternalRaftRequest{Put: r})
if err != nil {
return nil, err
}
return resp.(*pb.PutResponse), nil
}
It called raftRequest, eventually processInternalRaftRequestOnce will be called
Here is the core logic of Etcd submitting requests to the state machine for processing. I added detailed comments to this core code, Hope this helps you better understand the Put writing process.
This is step2 in Figure1 - Forwards to RAFT sub-system.
func (s *EtcdServer) processInternalRaftRequestOnce(ctx context.Context, r pb.InternalRaftRequest) (*apply2.Result, error) {
ai := s.getAppliedIndex()
ci := s.getCommittedIndex()
// If the server blocks too many requests, there is no apply, It will deny new requests coming in.
if ci > ai+maxGapBetweenApplyAndCommitIndex {
return nil, errors.ErrTooManyRequests
}
// Generate a unique ID for the request
r.Header = &pb.RequestHeader{
ID: s.reqIDGen.Next(),
}
// check authinfo if it is not InternalAuthenticateRequest
if r.Authenticate == nil {
authInfo, err := s.AuthInfoFromCtx(ctx)
if err != nil {
return nil, err
}
if authInfo != nil {
r.Header.Username = authInfo.Username
r.Header.AuthRevision = authInfo.Revision
}
}
// Convert pb.InternalRaftRequest request to byte sequence.
data, err := r.Marshal()
if err != nil {
return nil, err
}
if len(data) > int(s.Cfg.MaxRequestBytes) {
return nil, errors.ErrRequestTooLarge
}
id := r.ID
if id == 0 {
id = r.Header.ID
}
ch := s.w.Register(id)
cctx, cancel := context.WithTimeout(ctx, s.Cfg.ReqTimeout())
defer cancel()
start := time.Now()
// Call raft core library propose to Submit a request to raft.
err = s.r.Propose(cctx, data)
if err != nil {
proposalsFailed.Inc()
s.w.Trigger(id, nil) // GC wait
return nil, err
}
proposalsPending.Inc()
defer proposalsPending.Dec()
select {
case x := <-ch:
// Wait for request to succeed.
return x.(*apply2.Result), nil
case <-cctx.Done():
proposalsFailed.Inc()
s.w.Trigger(id, nil) // GC wait
return nil, s.parseProposeCtxErr(cctx.Err(), start)
case <-s.done:
return nil, errors.ErrStopped
}
}
Now, Let’s continue to dive into the implementation details of s.r.Propose(cctx, data), this will step into raft core library, you can find the code in https://github.com/etcd-io/raft
Firstly, we propose a Message with pb.MsgProp type to raft system, the entry contains our PutRequest data.
Then, leader node will call stepLeader to step this Message
func stepLeader(r *raft, m pb.Message) error {
// These message types do not require any progress for m.From.
switch m.Type {
...
if !r.appendEntry(m.Entries...) {
return ErrProposalDropped
}
r.bcastAppend()
leader call appendEntry to append a new entry to it’s log, This is step3’ - Persists the transaction to its own WAL.
func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {
li := r.raftLog.lastIndex()
for i := range es {
es[i].Term = r.Term
es[i].Index = li + 1 + uint64(i)
}
// Track the size of this uncommitted proposal.
if !r.increaseUncommittedSize(es) {
r.logger.Warningf(
"%x appending new entries to log would exceed uncommitted entry size limit; dropping proposal",
r.id,
)
// Drop the proposal.
return false
}
// use latest "last" index after truncate/append
li = r.raftLog.append(es...)
// The leader needs to self-ack the entries just appended once they have
// been durably persisted (since it doesn't send an MsgApp to itself). This
// response message will be added to msgsAfterAppend and delivered back to
// this node after these entries have been written to stable storage. When
// handled, this is roughly equivalent to:
//
// r.trk.Progress[r.id].MaybeUpdate(e.Index)
// if r.maybeCommit() {
// r.bcastAppend()
// }
r.send(pb.Message{To: r.id, Type: pb.MsgAppResp, Index: li})
return true
}
Next the leader node will ask peer RAFT nodes to replicate transation in their WAL by send AppendEntries request with r.bcastAppend().
This is the flow 3’’ in Figure1.
Leader node send AppendEntries message as described in the raft paper.
r.send(pb.Message{
To: to,
Type: pb.MsgApp,
Index: prevIndex,
LogTerm: prevTerm,
Entries: ents,
Commit: r.raftLog.committed,
})
When the message transport to peer follower node, peer follower node will call stepFollower
func stepFollower(r *raft, m pb.Message) error {
switch m.Type {
...
case pb.MsgApp:
r.electionElapsed = 0
r.lead = m.From
r.handleAppendEntries(m)
...
}
The peer node will Persists entry to its WAL (Figure1 step4) in function r.handleAppendEntries(m)
func (r *raft) handleAppendEntries(m pb.Message) {
// TODO(pav-kv): construct logSlice up the stack next to receiving the
// message, and validate it before taking any action (e.g. bumping term).
a := logSliceFromMsgApp(&m)
if a.prev.index < r.raftLog.committed {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})
return
}
if mlastIndex, ok := r.raftLog.maybeAppend(a, m.Commit); ok {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
return
}
r.logger.Debugf("%x [logterm: %d, index: %d] rejected MsgApp [logterm: %d, index: %d] from %x",
r.id, r.raftLog.zeroTermOnOutOfBounds(r.raftLog.term(m.Index)), m.Index, m.LogTerm, m.Index, m.From)
// Our log does not match the leader's at index m.Index. Return a hint to the
// leader - a guess on the maximal (index, term) at which the logs match. Do
// this by searching through the follower's log for the maximum (index, term)
// pair with a term <= the MsgApp's LogTerm and an index <= the MsgApp's
// Index. This can help skip all indexes in the follower's uncommitted tail
// with terms greater than the MsgApp's LogTerm.
//
// See the other caller for findConflictByTerm (in stepLeader) for a much more
// detailed explanation of this mechanism.
// NB: m.Index >= raftLog.committed by now (see the early return above), and
// raftLog.lastIndex() >= raftLog.committed by invariant, so min of the two is
// also >= raftLog.committed. Hence, the findConflictByTerm argument is within
// the valid interval, which then will return a valid (index, term) pair with
// a non-zero term (unless the log is empty). However, it is safe to send a zero
// LogTerm in this response in any case, so we don't verify it here.
hintIndex := min(m.Index, r.raftLog.lastIndex())
hintIndex, hintTerm := r.raftLog.findConflictByTerm(hintIndex, m.LogTerm)
r.send(pb.Message{
To: m.From,
Type: pb.MsgAppResp,
Index: m.Index,
Reject: true,
RejectHint: hintIndex,
LogTerm: hintTerm,
})
}
If Follower append entries to its log ok, it will send response message to leader node as below (step5. Confirms replication to its WAL).
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
If the leader node recived no reject response form follower node. it will call maybeCommit
func (l *raftLog) maybeCommit(at entryID) bool {
// NB: term should never be 0 on a commit because the leader campaigned at
// least at term 1. But if it is 0 for some reason, we don't consider this a
// term match.
if at.term != 0 && at.index > l.committed && l.matchTerm(at) {
l.commitTo(at.index)
return true
}
return false
}
to marks the transaction as ‘committed’ (In figure1 step6).
The next step, the raft core library will notify ectdserver to apply committed entries by the go channel s.r.apply().
func (s *EtcdServer) run() {
lg := s.Logger()
...
for {
select {
case ap := <-s.r.apply():
f := schedule.NewJob("server_applyAll", func(context.Context) { s.applyAll(&ep, &ap) })
sched.Schedule(f)
case leases := <-expiredLeaseC:
s.revokeExpiredLeases(leases)
case err := <-s.errorc:
lg.Warn("server error", zap.Error(err))
lg.Warn("data-dir used by this member must be removed")
return
case <-s.stop:
return
}
}
}
Finaly, all nodes will applies entries to MVCC store and backend.
You can find this process through the function call chain below.
s.applyAll(&ep, &ap) -> EtcdServer.applyEntries -> EtcdServer.apply -> EtcdServer.applyEntryNormal -> EtcdServer.applyInternalRaftRequest -> newlest applyV3 uberApplier.Apply -> uberApplier.dispatch -> applierV3backend.Put -> MVCC KV Write to BoltDB
Reference
- https://github.com/etcd-io/etcd
- https://etcd.io/docs/v3.6/